Hierarchical Patch VAE-GAN:
Generating Diverse Videos from a Single Sample
*Equal contribution.
We consider the task of generating diverse and novel videos from a single video
sample. Recently, new hierarchical patch-GAN based approaches were proposed
for generating diverse images, given only a single sample at training time. Moving
to videos, these approaches fail to generate diverse samples, and often collapse
into generating samples similar to the training video. We introduce a novel patchbased variational autoencoder (VAE) which allows for a much greater diversity
in generation. Using this tool, a new hierarchical video generation scheme is
constructed: at coarse scales, our patch-VAE is employed, ensuring samples are of
high diversity. Subsequently, at finer scales, a patch-GAN renders the fine details,
resulting in high quality videos. Our experiments show that the proposed method
produces diverse samples in both the image domain, and the more challenging
video domain.
Randomly Generated Videos
Randomly generated samples by our method as described in Figure 1 and in Section 4.2. Videos are shown as GIFs and so repeat continuosly. Training and generated videos each consist of 13 frames.
| Training Video |
|
Randomly Generated Samples |
 |
|
 |
 |
|
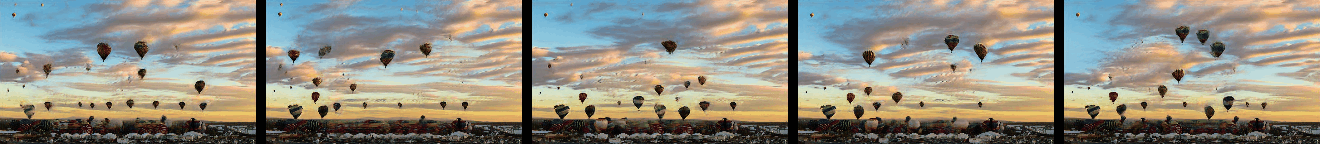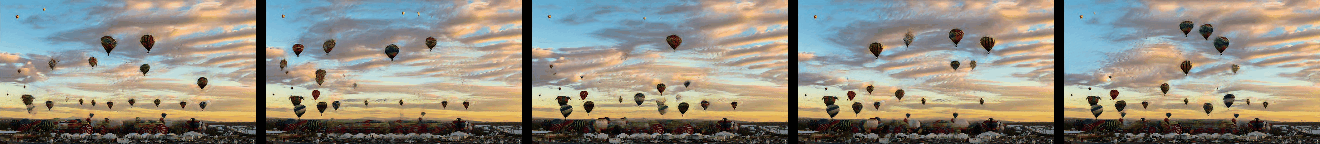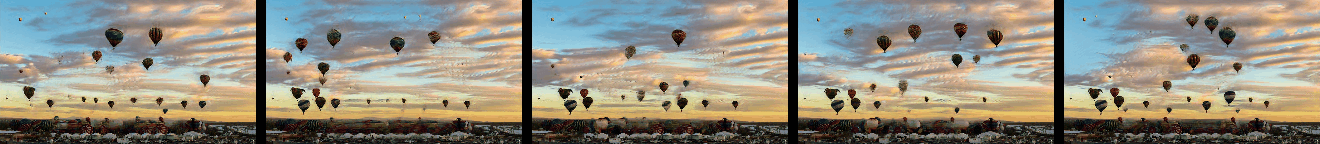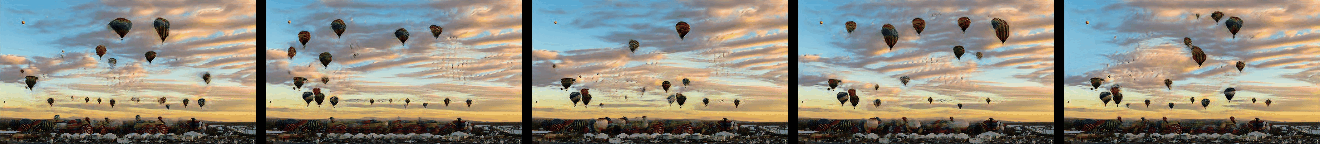 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
 |
 |
|
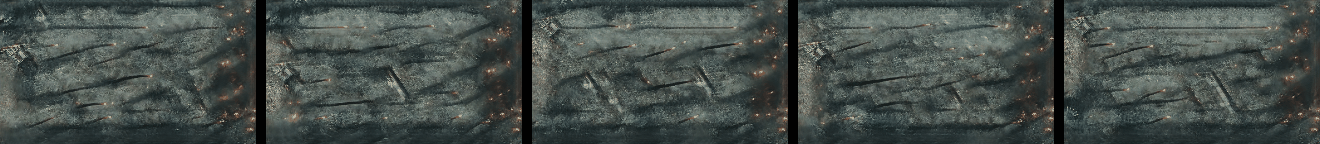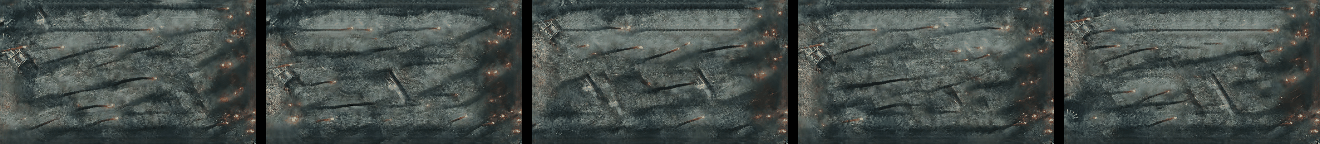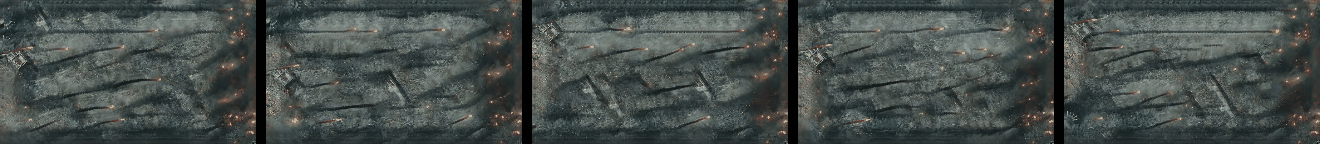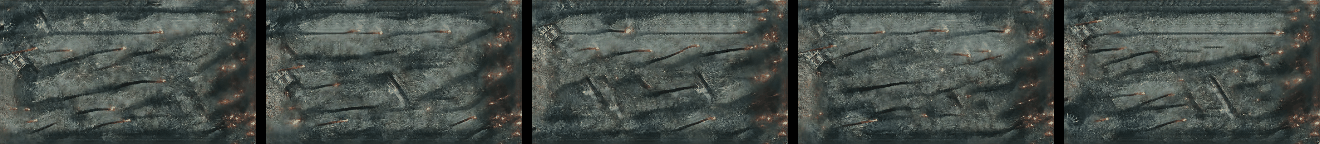 |
 |
|
 |
Longer Training Videos
As mentioned in Section 3.2, our method can also be trained on longer videos, thus generated further variability in outputs. We show a number of longer training videos (more then 13 frames) and associated randomly generated samples of 13 frames.
| Training Video |
|
Randomly Generated Samples |
 |
|
 |
 |
|
 |
 |
|
 |
Baselines Videos
Shown here are a number of video outputs of SinGAN and ConSinGAN baseline methods (with 2D convolutions replaced with 3D ones) as presernted in the user study of Section 4.2.
| Training Video |
|
SinGAN (3D) [24] |
|
|
 |
|
|
 |
| Training Video |
|
ConSinGAN (3D) [28] |
|
|
 |
|
|
 |
Effect of Number of VAE Levels
Effect of the number of VAE levels M on the generated samples as described in Figure 6 and Section 4.2. N is set to 9, and so a total of 10 levels are trained.
In addition a comparsion to SinGAN and ConSinGAN (with 2D convolutions replaced with 3D ones) is given.
| Training Video |
|
SinGAN (3D) [24] |
|
|
 |
| Training Video |
|
ConSinGAN (3D) [28] |
|
|
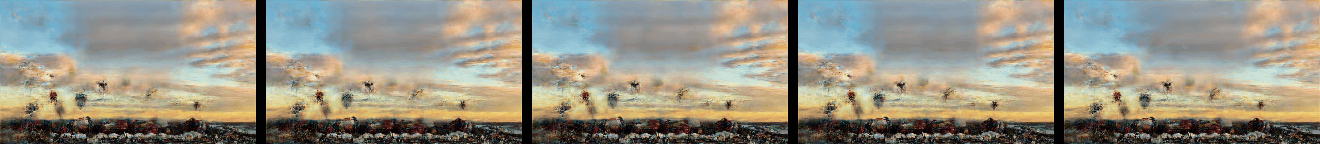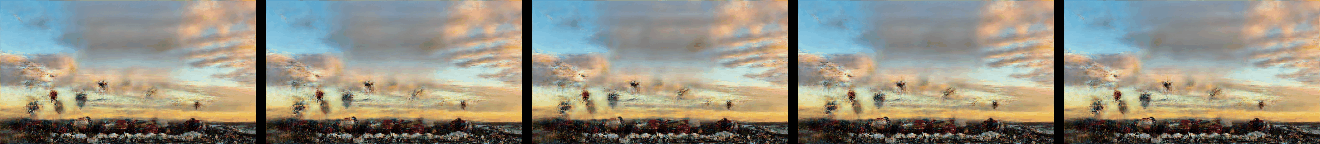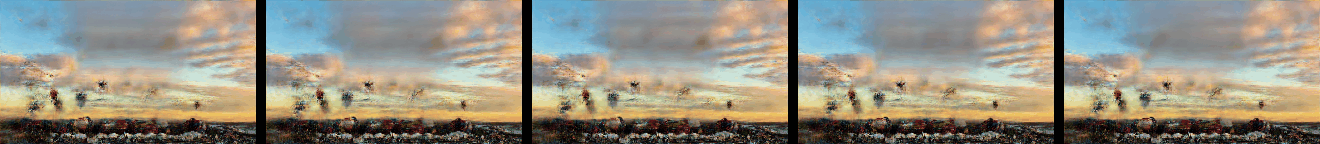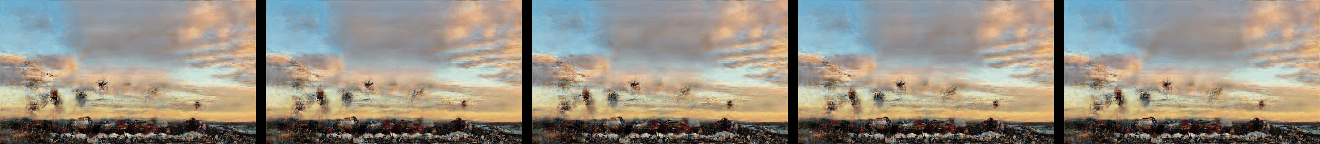 |
| Training Video |
|
Single VAE level (M=1) |
|
|
 |
| Training Video |
|
Single GAN level (M=9) |
|
|
 |
| Training Video |
|
Our Method (M=3) |
|
|
|
Super Resolution
Training on a video of a standard 256×192px resolution and producing random videos of higher 1024×256px resolution.
| Training Video |
|
Generated Samples |
 |
|
 |
Single Image Generation
Additional images generation results and comparison to baselines as described in Figure 7 and Section 4.2.
| SinGAN [24] |
ConSinGAN [28] |
Our Method (2D) |
 |
 |
 |
 |
 |
|
|
|
 |
 |
 |
 |
 |
|
|
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
|
|
 |
 |
 |
 |
 |
|
|
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
|
|
 |
 |
 |
 |
 |
|
|
|
 |
 |
 |
 |
 |
Single Image Generation - Additional Tasks
| |
Train Example |
Input |
SinGAN [24] |
ConSinGAN [28] |
Our Method (2D) |
| Harmonization |
 |
 |
 |
 |
 |
| Paint-to-Image |
 |
 |
 |
 |
 |
| Editing |
 |
 |
 |
 |
 |